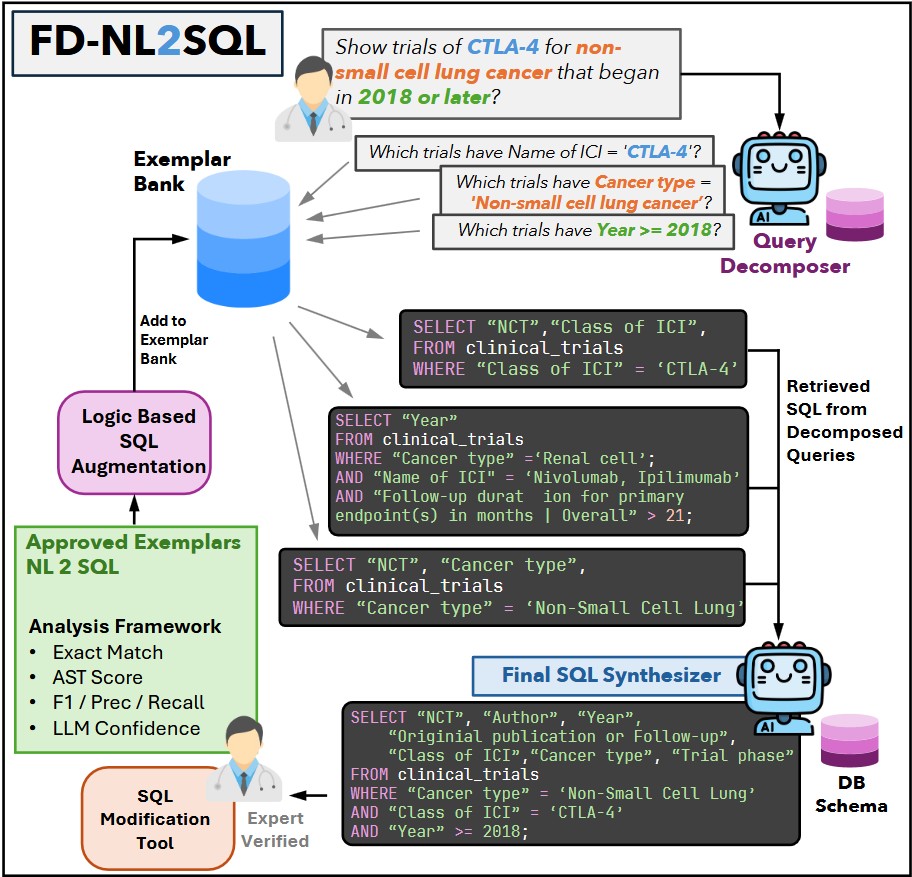
Why this problem matters
Clinical evidence review often depends on ad hoc, multi-constraint questions over cancer type, checkpoint inhibitor class, biomarkers, follow-up windows, endpoints, treatment combinations, and trial phase. Those are difficult to express reliably through keyword search and tedious to encode in SQL.
FD-NL2SQL targets this gap with a domain-aware pipeline built specifically for oncology trial data, where brittle or clinically implausible queries are costly and transparency matters.